Stripe-CTF 3 Writeup
30 Jan 2014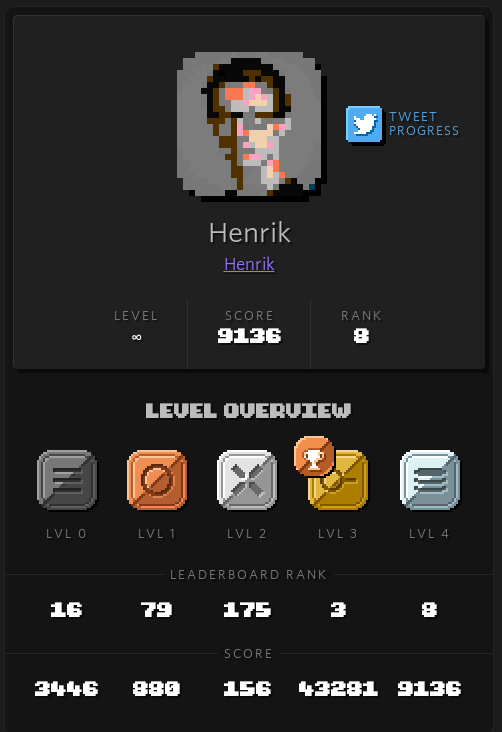
~~Note: I’ll add the source once submissions are off. Since the contest is *officially over** here goes the text part of it, I doubt anyone will quickly implement all of it.~~ It’s all on Github now!*
Note: I posted a screenshot of Google Analytics here so that you can take a look of what a 4th place on Hacker News looks like in terms of visits.
Stripe-CTF is a recurring programming challenge which completed its third iteration just hours ago. I have not participated in other iterations of Stripe’s code challenge, primarily because I have heard about it the first time only two weeks ago on HN. While the last iterations concerned web security, this iteration had the topic of distributed systems. Our credo is frequently to first scale the system on one node before you think about scaling it out so that was my general approach to the problems which were in essence:
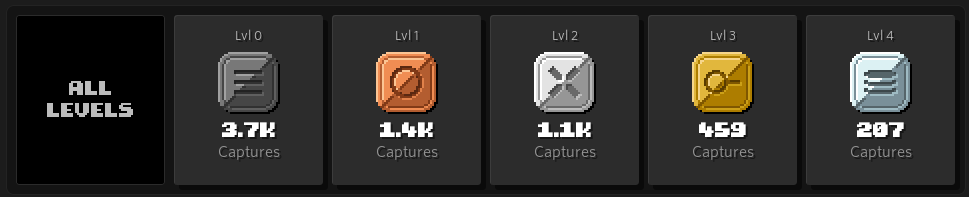
- Determine whether a specific word is contained in a dictionary (single node, fastest wins)
- Build a git commit with a SHA1 which is lexicographically smaller than a given difficulty hash, for instance 0x00000000f (whatever resources you own, compete against others in mining)
- Filter out a DDoS attack while also load balancing (single node with multiple backend nodes)
- Find a string anywhere inside a set of files which could be indexed beforehand. (4 nodes, fastest search latency wins)
- Build a distributed SQLite cluster withstanding node failures and communication errors which maintains a single truth at all time (most queries over 30 seconds with least traffic wins)
The Good
- All challenges came with a (most of the time terribly slow or buggy) reference solution. This is great. Always do this! It encourages people to start hacking and improving and you can start being better than the reference solution much quicker than you could build a good one yourself. First, you essentially compete against the reference implementation, then, when you have completely understood the problem you can come up with a great solution which can then outrank all other players. Very good.
- Every problem was initially implemented in a different language. I don’t necessarily think that you need 5 different imperative languages to most efficiently solve each problem and my solutions are certainly biased towards being written in C++. Still, reading implementations in 5 different languages and using 2 of them for my own solutions broadened my knowledge of said languages. For instance, the reference for 5. was written in Go which I found a new appreciation for due to its fantastic library. Being able to understand many languages if only to improve on them in something else is a great skill and you were able to exercise it in depth during the CTF.
- Awesome backend system. This surely took some time to build for Stripe. There were bugs and downtimes but all in all I really hammered their backend and it worked fairly well. What I especially like about it is that you could specify how to build your application in a bash script with full internet access so you were able to really use ANY language and library you wanted. I used it a lot, for instance to download Intel Thread Building Blocks and to mess with binary data injected into my program using objdump.
The Bad
- Do not fuck with the deadline. Seriously. The backend was down two half-days, always during the day in Europe. I am European, it sucked for me. But it’s not like I wasn’t able to test locally and continue working on my solution, it was just a nuisance. What I can not stand though is being told that I can focus on everything else starting Wednesday 11am PT and then that gets moved to “maybe 24 hours longer or so, but no guarantees”. Either you actually move the deadline to another fixed point in time or you don’t. There’s nothing good in between. In any case, even though I feel I was one of the people being hurt the most by the downtimes during European daytime, I vote for not moving a challenge’s end. Ever.
- Small test-cases. I know this is tough. It is tough on Codematch which I build for my students. But it is no excuse. For solutions which rank somewhere in position 700 out of 4000 it doesn’t matter. For the top 20, your final score was mostly determined by how overloaded the servers were (bad) or how long the network latency was during your run (MUCH worse). Problem 4. was tested with maybe 50 search strings. My system needs about 0.005 milliseconds to find all matches and return the json answer. This is so far below network latency that algorithmic improvements matter zip. Why not ask for 500 answers in ONE query and receive one answer. I figure most of the time those who make up a challenge don’t expect people to solve it 10000x faster than the naive solution but it happens and those people would really like to see how well they fare against the other top submitters, not how high the network latency is.
- Make sure people cheat less. I’ll get to that; it just seems cooler implementing a good solution to the actual problem instead of searching for ways around it in this one specific scenario.
Anyway. It was awesome. Just improve on the bad and I’ll be game next time. Let’s talk about each problem I actually care for and what solution I built. Everything’s on Github so feel free to play with it if you like.

Level 0: Dictionary Lookups
Originally implemented as a naive scan through the dictionary, I imagine everyone came up with using a hash table or at least some sort of logarithmically searchable data structure like tree or sorted vector. I actually pushed it a little further and hacked together my own hash table which gives a huge performance boost compared to C++11’s std::unordered_set. There’s multiple reasons for that which I will briefly summarize here:
- Use a fast hash function of fairly high quality For short strings, as is the case for this challenge, CRC32 computed in hardware performance very well. The reason for that is that CRC32 is fairly equally distributed on about half of the 32 bits and exhibits an “okish” distribution on the rest. But what it lacks in quality it makes up for in time to compute the hash as it is available on all CPUs starting with the first Intel I5. Also, it is trivial to unroll the loop for words with less than 32 characters as can be seen in my implementation. I have not found a better hash for this particular challenge.
- Use a power-of-two sized hash table This sounds counter intuitive as many people use a prime number as the hash table size. Prime numbers are (maybe) better to avoid clusters, but that’s what we have a good hash function for. Using a table sized to a power has the huge advantage of being able to compute the remainder using a bit-mask instead of the modulo operation saving a massive (try it!) amount of time in lookups and inserts.
- Don’t allow the hash to grow This is of course only sensible if you know the size of the dictionary which your hash is going to contain. In this case, it turns out to be hard to find dictionaries which are much bigger than the one used in the contest. Also, since the dictionary was never changed, setting your hash size to something bigger than 200000 * 1.5 seemed like a pretty save bet.
- Do not use
std::string, contain the strings inside the hash buckets This avoids cache misses and is totally feasible for words of fairly short length. If you do not like the memory overhead, put all words into a vector and reference them using something like boost::string_ref.std::stringallocates for each string and thus frequently exhibits terrible memory locality.
With a solution like that written in - for instance - C++ you get a very solid result. You are still far away from the ~4000 points the Top 20 including me had in this challenge. This is because I can say with great confidence that we all cheated. That works as follows:
- Do not lookup the word, lookup the has if your hash function is good, you might not encounter a false positive match. It worked for me. This is of course not a good solution because it’s not exact but it makes for implementation MUCH faster.
- Do not create the hash table during runtime but during compile time. Sounds tricky at first but it’s a breeze. You write a second program which build a hash table and write it to disk using
std::ofstream::write. Then you embed it into your final solution usingobjcopyand that’s pretty much it. It is a neat trick I learned during this contest and I am sure it’s gonna be useful at some point. Read more online, for example here, or look at my Makefile and final solution on Github.
This moved my submission to somewhere inside the Top 20 and from what I saw the servers were simply too overloaded and the number of queried words to small to get any meaningful ranking between the top submissions.

Level 1: Gitcoins
I find this problem is amazing both in the way it relates to the rise of bitcoins and how git works internally. I learned a bunch and it was fun. Essentially, you had to write a miner which build valid git commit records. The SHA1 hash of that value had to be lower than a certain given SHA1 value which varied over the course of the contest. Finding a commit with a suitable SHA1 hash required about a billion hash operations on average at some point during the contest.
I wrote a multi-threaded miner in C++ which was good enough for my purposes. I got about 7 million hashes per second per thread on my machine and mined a couple of gitcoins. It’s still a waste of compute resources so I moved on fairly quickly but I suspect someone rewrote a GPU miner from a past contest and was able to mine a lot more than people using a CPU miner. My miner is here if you are curious.

Level 2: DDoS Filter
This problem I liked the least but it might just be because it is not ranked by how fast your code is. You were given a proxy application which filters incoming network traffic and proxies it through to a number of backend servers. You had to filter connections which tried to essentially spam the server while letting good-natured connections through. This one took 5 lines of javascript (the original was written in node) to pass the tests at which point I moved on. See [GitHub] for my revised solution in CoffeeScript.
Level 3: Codesearch
Given a set of files, index them such that you can efficiently answer substring queries by returning file and line where a match was found. You were given 4 nodes connected by tcp links to build an application for. In my view, there are two key factors which determine success:
- Using a suitable data structure for lookups, I think a suffix array works best but your mileage may vary.
- Not using more than 1 node.
With the suffix array, you can answer substring queries by performing a binary search on a vector. Granted, you have to do side lookups into another vector which contains the actual strings but this is dirt-cheap as it is in its nature a logarithmic algorithm. Time to prepare the suffix array was not counted against your score so I figure it’s very hard to find a better solution which does not require insane amounts of memory. I briefly thought about building a hash table for each substring but that would have been a much bigger data structure for only a small speedup. Also, memory was said to be limited to 500MiB (something I never hit so who knows) and would thus have forced me to use more than one node which - in my view - is a terrible idea.
The reason for using more than one node being bad is network latency. You receive each query as an HTTP request and the client does not use keep-alive and opens a new connection for each request. The latency caused by this input mechanism is at least 20 times bigger than the time required to find the answer to the request. Therefore, a) tuning your algorithm yields you almost no speedup due to the high fixed network delay once you use a suffix array or similar structure and b) forwarding the request to other servers allows you to reduce the size of the index but given that the algorithm is logarithmically complex in the size of the index that really doesn’t help much compared to the added latency.

I actually went one step further and also hacked together my own HTTP server to (hopefully) reduce latency some more. Since you receive only one query at a time it does not require threads or forking so it is rather compact. Before, I used an extremely simple HTTP server based on boost::asio.
This was a great task to begin with, I had never used a suffix array before. It could have been even greater though: A score based on throughput and latency as well as say factor 100 more queries and this could have been the only question in the challenge and still be extremely interesting and challenging.
Level 4: Distributed SQLite Cluster
I am a database geek, this is awesome. Although it has nothing to do with databases but is all about distributed systems, but this was to be expected from a distributed systems contest. You are given an implementation of a cluster node with a broken consensus protocol. Your job is to change it such that each SQL query given to any node in the cluster is applied at most once to the cluster state and its state change is never lost. Also, your cluster has to make progress even when nodes fail and links break.
For this challenge, Stripe actually wrote a very decent network simulator called Octopus. It only works using UNIX domain sockets but they give an example of how to use those easily in Go which was used for their example implementation. The reason they probably chose Go is because there is a library implementing Raft, a distributed consensus protocol, for Go. From how their example submission was implemented, go-raft was essentially a drop-in addon which added raft to the cluster. It took me about 2 hours to understand how to plug everything together and raft was working.

Although I now had a join consensus protocol working, the challenge was far from over. Raft is a strong master consensus protocol which means that only the master can issue commands to the cluster. This complicates the solution dramatically, as the simulation used to score this challenge submits SQL queries to all nodes and not just the master. To add insult to injury, the client submitting the requests can not be redirected to submit them to the master due to using UNIX domain sockets (it does listen to 302 found requests, imho, but it does not switch the UNIX domain socket used to contact the master as far as I know). Therefore, each cluster node needs to be able to forward requests to the master so that the master can apply the request to the cluster. This is tricky.
Forwarding requires that a) the query is only executed once and b) the result is send back to the node which initially received the request and then forwarded to the client, also exactly once. I did not see a) coming as I thought network links were only delayed or jitter was applied to them, not disconnected. That hit me hard and I had to rewrite my forwarding protocol. I ended up generating a unique id for each incoming request and handing it of to whoever is currently the master node. The unique id was used so that the receiving node would only execute the query once and never twice. There are edge cases, where the receiver is no longer the master and again needs to forward the SQL query which I dealt with but will not explain here, see the sqlHandler in this file for details.
Result submission was done by tracking which state updates were applied to the cluster. When a query which was originally received at the current node was applied to the current node, the result of that query was also submitted to the client guaranteeing exactly-once semantics for result delivery.
The last part was getting a good (>1000) score. I did this by improving the performance of state chance applications to the state machine modeled by each cluster node. This only occurred to me on the last day of the contest and greatly (5x) improved my final result. Go was very helpful here as go-routines and channels make it very simple to implement this; see this file for more.
I also improved the SQLite database speed by running it in memory, starting it once and sending all queries to the same, permanently running SQLite process through go channels. It’s simple and yielded a huge performance increase in SQL query processing.
Summary
I am happy with my results, apparently I am a pretty decent programmer, 8 out of ~4000 ain’t too bad especially when scores vary by a factor of 3x between executions which makes getting a great score a game of chance. I learned quite a lot during the contest, I can highly recommend solving each problem yourself. Thanks Stripe!