CodeChef Feelgood Therapy
26 Sep 2013Coding challenges are great for anyone who codes, likes to win and has too much time on his hands. I participated in an extensive one earlier this year, I learned a lot. Coding challenges have been institutionalized, one platform offering such challenges is CodeChef. There is different types of challenges on CodeChef. One such type is code golf where the goal is keeping the source code as short as possible, to me, something utterly useless. Short, readable code is great, code like :(){ :|:&};: is not. More interesting challenges are timed, hard problems. I am not the lunch-time challenge type where time limits range between one and a couple of hours but a contest lasting for say a week gets my attention.
From the little if read on CodeChef so far, this seems to be very India-centric in its nature. Universities hold competitions for their students, sometimes there is apparently an Indian vs. non-Indian leaderboard.
The Challenge and a Solution.
If you are starting to code, most challenges will upset you greatly. I chose to try one of the training challenges, rated easy. Algorithmically, that might be the case, from a technical point of view this is certainly wrong. I am fairly certain that the challenge is impossible to solve in any language which is not compiled down to machine code. I am even more certain, that winning (in terms of lowest runtime) is out of the question. This is not because I inherently despise VM-based languages except for trivialities like web programming (I do), but because of the way many contests are run.
Let’s look at the problem at hand first, it is from graph theory, the mathematically disinclined are recommended to skip this paragraph. Given an undirected graph G(V,E) where V denotes the set of vertexes and E denotes the set of edges; edges have an associated weight. For all (v1,v2) such that v1,v2 are elements of V and v1!=v2, find the path p1 which connects v1 with v2 such that there is no other path p2 for which mincost(p2) > mincost(p1). $mincost(p)$ is defined as min( { weight(e) | e \in p } ), that is, the minimum weight which is associated with an edge on the path. Essentially, for every pair of vertexes, one has to find the minimum weight of the path which has the lowest minimum weight of all paths between those two vertexes.
It is immediately obvious that a brute force solution will not yield sufficient performance as the time-limit set on CodeChef is 3 seconds and the number of nodes can be up to one thousand. This means that potentially, (1000*1000)/2 vertex-pairs have to be examined. Luckily, the algorithmic part of this exercise is indeed fairly straight forward. Since we are trying to avoid “cheap” edges with a low associated weight and the number of edges we use on a path is not relevant, we simple need to build a simpler graph which connects all nodes and uses high-weight edges. This is essentially the inverse of a minimal spanning tree (or: a minimal spanning tree with all weights inverted). Given that tree, we just have to generate the all-pairs best paths and have solved the challenge.
A CodeChef Player’s Tool Chest (see GitHub)
While implementing a minimal spanning tree algorithm is fairy straight forward given the abundant supply of examples, even the best implementation of the actual algorithm will not help us onto the leaderboard, let alone be the fastest entry. This is because both input and output are massive in size compared to the work the correct algorithm has to perform.
The input format is
<number of vertexes>
<number of edges>
<from> <to> <weight>
<from> <to> <weight>
...
<from> <to> <weight>
and a simple parser can be written using C++ streams, for instance:
struct Edge { uint32_t from; uint32_t to; uint32_t weight; }
uint32_t vertexCount; uint32_t edgeCount;
std::cin >> vertexCount >> edgeCount;;
std::vector<Edge> edges(edgeCount);
for (uint32_t index=0; index<edgeCount; ++index) {
Edge e;
std::cin >> e.from >> e.to >> e.weight;
edges.push_back(e);
}
/* code untested */This is very readable code and it does not use evil methods like fscan. Unfortunately, it is also incredibly slow. I submitted a parser like this (without any other code to solve anything) to see how fast it was and it timed out. I was so shocked that I uploaded an empty solution to see if that would time out too – it didn’t.
As with every issue, a quick search on StackOverflow reveals that std::cin is indeed relatively slow. Relatively, as it turns out can translate to 100x, which is the speedup I gained from modifying the parser, my modifications:
- Buffer
stdin. - Parse numbers without
scanf. - Iterate exclusively using pointers.
The resulting reader class with some details stripped looks like this:
class BufferedReader {
/// Size of the input buffer
static const uint64_t BufferSize = 1024*200;
/// The buffer
char buffer[BufferSize];
/// The current and end pointer
const char* currentPtr;
const char* endPtr;
public:
...
bool replenish() { ... /* loads more bytes into the buffer */ }
/// Reads a number from the buffer
template<class T>
T readNumber() {
T number=0;
while (true) {
for (; currentPtr!=endPtr; ++currentPtr) {
if (*currentPtr>='0'&&*currentPtr<='9') {
number = (number*10) + (*currentPtr - '0');
} else {
goto done;
}
}
if (!replenish()) break;
}
done:
return number;
}
...
};Before you mock the use of goto, breaking out multiple nested loops is actually the only allows usage that does not cause this to happen. Using this optimized parser lead to the submission not timing out but instead failing with “wrong result” – as no result was returned by my implementation so far. The runtime for parsing was returned though and now amounted to roughly 1% of what the competitors had as their total runtime.
The algorithm for solving the challenge can be found in the linked git repository on GitHub. A detailed discussion might follow in a later post but is omitted here to focus on the tooling needed for challenge participation.
For the output of the solution which is a |V| times |V| matrix, I opted for preallocating all memory required for the output and flushing it out in one write. This tremendously simplifies the writer class and should be sufficiently fast for an output in the order of a few megabytes.
The first run of the complete solution worked and yielded a correct result – albeit at a too leisurely pace for my taste: 16.09 (unit missing from CodeChef, that actually really sucks). To be number one on the leaderboard, roughly 2x are required. Quick testing and profiling on a generated random graph shows that some time is spend generating the output. A separate run of the PoorMansProfiler actually reveals, that 50% of the wallclock time is spend writing the output, specifically, calling itoa.
class FixedWriter {
/// The output buffer
std::vector<char> buffer;
/// The index inside the buffer
uint64_t index;
public:
/// Constructor
FixedWriter(uint64_t maxOutputSize) : index(0) {
buffer.resize(maxOutputSize);
}
/// Writes an int into the stream
template<class T>
void writeNumber(const T& value) {
//index+=sprintf(&buffer[index],"%d",value);
FormatUnsigned<T> i(value); // <= see github repo for implementation!
for (const char* ptr=i.c_str(); *ptr!='\0'; ++ptr) {
buffer[index++]=*ptr;
}
}
/// Writes a character
void writeChar(char c) {
buffer[index++]=c;
}
/// Flush to fd
void flush(int fd) {
auto len=write(fd,buffer.data(),index);
assert(len==index);
}
};
Googling “optimizing itoa” actually yields plenty results and is left as an exercise to the reader. The finished output writer is displayed here for reference. The key part is swapping out sprintf for an optimized routine inspired by the more complete one authored by Victor Zwerovich (GitHub).
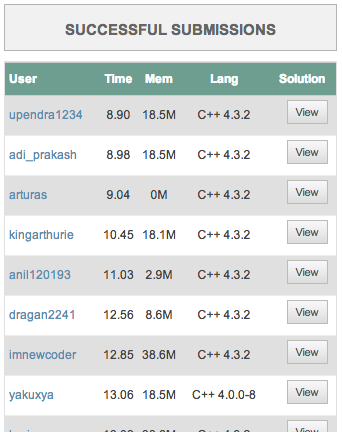
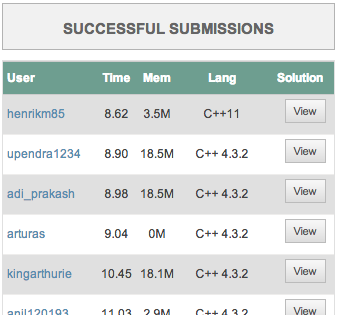
And alas, 2x, top of the leaderboard. Remember, the problem was classified as easy. I figure much of this code is not entry level code. A better metric for determining the difficulty of a task is probably the number of successful submissions.
For this one, it is less than 50 entries, some tasks have thousands…