We use Docker for various teaching webservices (Codematch, Xquery, Datalog) we want to offer to students but which should not cause our webserver to be more exposed. Docker has been good so far and we have already used the architecture to migrate all containers from the original dev host to the production webserver host. Here, we’ll talk about switching from AUFS to Devicemapper as a storage backend.
Why device mapper?
I can not attest to either storage backend being strictly better or worse than the other. However, for us the benefit is being able to run IBM DB2 without resorting to mounting an external volume for the DB2 container. This is beneficial, as using external storage break the versioned architecture of docker while keeping all data inside the container’s filesystem yields a nice separation of concerns.
1) Exporting all important images
We first committed each image we care for so that we had the most recent version tagged somewhere with all changes included. This can be done roughly like this
docker ps -a
# for each container you care for, stop and then commit it
docker commit e198aac7112d export/server1
docker commit a312312fddde export/server2
Then, we saved each image to a tar archive using the docker save command. Beware that docker save streams the tarred and gzipped output to stdout so you better redirect it into a file like so:
docker save export/server1 > export_server1.tar.gz
docker save export/server2 > export_server2.tar.gz
This gives you loadable copies of each of your important images. Alternatively, you could also export the container using export and import but I had less success with this: import failed to load a 1500MB export (I killed it after 15 hours of “importing”). Your milage may vary.
2) Switching storage backends
On ubuntu, this is simple. You want to add an argument to the docker deamon when it’s launched on system startup. Storage selection is done using the --storage-driver=x flag. AUFS seems to be the default so I changed /etc/default/docker to enable device mapper:
# Use DOCKER_OPTS to modify the daemon startup options.
DOCKER_OPTS="--storage-driver=devicemapper"
and restarted docker. With this, all containers and images should be gone (as there are none in devicemapper storage, if you removed the command line options, you’d see everything again). Now we import the original images like this:
This should actually allow you to start each image just like before except that you are running using the device mapper backend now. Of course, once you are confident that everything works as expected, you can get rid of the original images and containers stored in AUFS.
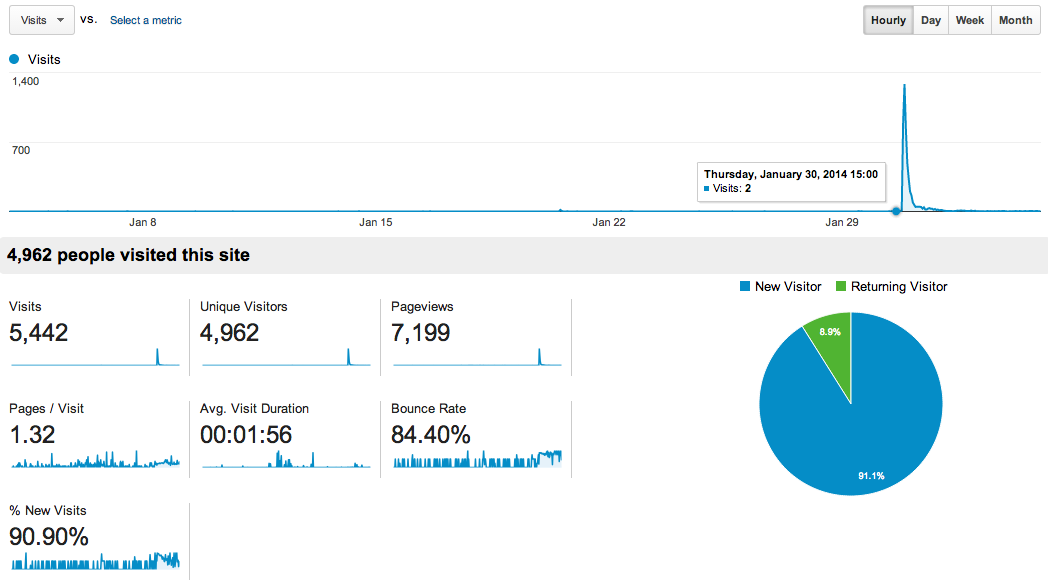
My Stripe-CTF Writeup actually made it 4th place on HackerNews and I just wanted to share how that looks in Google Analytics. Sufficient to say I was very happy with hosting a static, Jekyll generated blog on Github.io when I was the realtime analytics numbers climb beyond 300 concurrent visitors. Also, my Alexa rank jumped about 25,000,000 places to 300000th most visited website in the US. Good times, thank you.
~~Note: I’ll add the source once submissions are off. Since the contest is *officially over** here goes the text part of it, I doubt anyone will quickly implement all of it.~~ It’s all on Github now!*
Note: I posted a screenshot of Google Analytics here so that you can take a look of what a 4th place on Hacker News looks like in terms of visits.
Stripe-CTF is a recurring programming challenge which completed its third iteration just hours ago. I have not participated in other iterations of Stripe’s code challenge, primarily because I have heard about it the first time only two weeks ago on HN. While the last iterations concerned web security, this iteration had the topic of distributed systems. Our credo is frequently to first scale the system on one node before you think about scaling it out so that was my general approach to the problems which were in essence:
Determine whether a specific word is contained in a dictionary (single node, fastest wins)
Build a git commit with a SHA1 which is lexicographically smaller than a given difficulty hash, for instance 0x00000000f (whatever resources you own, compete against others in mining)
Filter out a DDoS attack while also load balancing (single node with multiple backend nodes)
Find a string anywhere inside a set of files which could be indexed beforehand. (4 nodes, fastest search latency wins)
Build a distributed SQLite cluster withstanding node failures and communication errors which maintains a single truth at all time (most queries over 30 seconds with least traffic wins)
The Good
All challenges came with a (most of the time terribly slow or buggy) reference solution. This is great. Always do this! It encourages people to start hacking and improving and you can start being better than the reference solution much quicker than you could build a good one yourself. First, you essentially compete against the reference implementation, then, when you have completely understood the problem you can come up with a great solution which can then outrank all other players. Very good.
Every problem was initially implemented in a different language. I don’t necessarily think that you need 5 different imperative languages to most efficiently solve each problem and my solutions are certainly biased towards being written in C++. Still, reading implementations in 5 different languages and using 2 of them for my own solutions broadened my knowledge of said languages. For instance, the reference for 5. was written in Go which I found a new appreciation for due to its fantastic library. Being able to understand many languages if only to improve on them in something else is a great skill and you were able to exercise it in depth during the CTF.
Awesome backend system. This surely took some time to build for Stripe. There were bugs and downtimes but all in all I really hammered their backend and it worked fairly well. What I especially like about it is that you could specify how to build your application in a bash script with full internet access so you were able to really use ANY language and library you wanted. I used it a lot, for instance to download Intel Thread Building Blocks and to mess with binary data injected into my program using objdump.
The Bad
Do not fuck with the deadline. Seriously. The backend was down two half-days, always during the day in Europe. I am European, it sucked for me. But it’s not like I wasn’t able to test locally and continue working on my solution, it was just a nuisance. What I can not stand though is being told that I can focus on everything else starting Wednesday 11am PT and then that gets moved to “maybe 24 hours longer or so, but no guarantees”. Either you actually move the deadline to another fixed point in time or you don’t. There’s nothing good in between. In any case, even though I feel I was one of the people being hurt the most by the downtimes during European daytime, I vote for not moving a challenge’s end. Ever.
Small test-cases. I know this is tough. It is tough on Codematch which I build for my students. But it is no excuse. For solutions which rank somewhere in position 700 out of 4000 it doesn’t matter. For the top 20, your final score was mostly determined by how overloaded the servers were (bad) or how long the network latency was during your run (MUCH worse). Problem 4. was tested with maybe 50 search strings. My system needs about 0.005 milliseconds to find all matches and return the json answer. This is so far below network latency that algorithmic improvements matter zip. Why not ask for 500 answers in ONE query and receive one answer. I figure most of the time those who make up a challenge don’t expect people to solve it 10000x faster than the naive solution but it happens and those people would really like to see how well they fare against the other top submitters, not how high the network latency is.
Make sure people cheat less. I’ll get to that; it just seems cooler implementing a good solution to the actual problem instead of searching for ways around it in this one specific scenario.
Anyway. It was awesome. Just improve on the bad and I’ll be game next time. Let’s talk about each problem I actually care for and what solution I built. Everything’s on Github so feel free to play with it if you like.
Level 0: Dictionary Lookups
Originally implemented as a naive scan through the dictionary, I imagine everyone came up with using a hash table or at least some sort of logarithmically searchable data structure like tree or sorted vector. I actually pushed it a little further and hacked together my own hash table which gives a huge performance boost compared to C++11’s std::unordered_set. There’s multiple reasons for that which I will briefly summarize here:
Use a fast hash function of fairly high quality For short strings, as is the case for this challenge, CRC32 computed in hardware performance very well. The reason for that is that CRC32 is fairly equally distributed on about half of the 32 bits and exhibits an “okish” distribution on the rest. But what it lacks in quality it makes up for in time to compute the hash as it is available on all CPUs starting with the first Intel I5. Also, it is trivial to unroll the loop for words with less than 32 characters as can be seen in my implementation. I have not found a better hash for this particular challenge.
Use a power-of-two sized hash table This sounds counter intuitive as many people use a prime number as the hash table size. Prime numbers are (maybe) better to avoid clusters, but that’s what we have a good hash function for. Using a table sized to a power has the huge advantage of being able to compute the remainder using a bit-mask instead of the modulo operation saving a massive (try it!) amount of time in lookups and inserts.
Don’t allow the hash to grow This is of course only sensible if you know the size of the dictionary which your hash is going to contain. In this case, it turns out to be hard to find dictionaries which are much bigger than the one used in the contest. Also, since the dictionary was never changed, setting your hash size to something bigger than 200000 * 1.5 seemed like a pretty save bet.
Do not use std::string, contain the strings inside the hash buckets This avoids cache misses and is totally feasible for words of fairly short length. If you do not like the memory overhead, put all words into a vector and reference them using something like boost::string_ref. std::string allocates for each string and thus frequently exhibits terrible memory locality.
With a solution like that written in - for instance - C++ you get a very solid result. You are still far away from the ~4000 points the Top 20 including me had in this challenge. This is because I can say with great confidence that we all cheated. That works as follows:
Do not lookup the word, lookup the has if your hash function is good, you might not encounter a false positive match. It worked for me. This is of course not a good solution because it’s not exact but it makes for implementation MUCH faster.
Do not create the hash table during runtime but during compile time. Sounds tricky at first but it’s a breeze. You write a second program which build a hash table and write it to disk using std::ofstream::write. Then you embed it into your final solution using objcopy and that’s pretty much it. It is a neat trick I learned during this contest and I am sure it’s gonna be useful at some point. Read more online, for example here, or look at my Makefile and final solution on Github.
This moved my submission to somewhere inside the Top 20 and from what I saw the servers were simply too overloaded and the number of queried words to small to get any meaningful ranking between the top submissions.
Level 1: Gitcoins
I find this problem is amazing both in the way it relates to the rise of bitcoins and how git works internally. I learned a bunch and it was fun. Essentially, you had to write a miner which build valid git commit records. The SHA1 hash of that value had to be lower than a certain given SHA1 value which varied over the course of the contest. Finding a commit with a suitable SHA1 hash required about a billion hash operations on average at some point during the contest.
I wrote a multi-threaded miner in C++ which was good enough for my purposes. I got about 7 million hashes per second per thread on my machine and mined a couple of gitcoins. It’s still a waste of compute resources so I moved on fairly quickly but I suspect someone rewrote a GPU miner from a past contest and was able to mine a lot more than people using a CPU miner. My miner is here if you are curious.
Level 2: DDoS Filter
This problem I liked the least but it might just be because it is not ranked by how fast your code is. You were given a proxy application which filters incoming network traffic and proxies it through to a number of backend servers. You had to filter connections which tried to essentially spam the server while letting good-natured connections through. This one took 5 lines of javascript (the original was written in node) to pass the tests at which point I moved on. See [GitHub] for my revised solution in CoffeeScript.
Level 3: Codesearch
Given a set of files, index them such that you can efficiently answer substring queries by returning file and line where a match was found. You were given 4 nodes connected by tcp links to build an application for. In my view, there are two key factors which determine success:
Using a suitable data structure for lookups, I think a suffix array works best but your mileage may vary.
Not using more than 1 node.
With the suffix array, you can answer substring queries by performing a binary search on a vector. Granted, you have to do side lookups into another vector which contains the actual strings but this is dirt-cheap as it is in its nature a logarithmic algorithm. Time to prepare the suffix array was not counted against your score so I figure it’s very hard to find a better solution which does not require insane amounts of memory. I briefly thought about building a hash table for each substring but that would have been a much bigger data structure for only a small speedup. Also, memory was said to be limited to 500MiB (something I never hit so who knows) and would thus have forced me to use more than one node which - in my view - is a terrible idea.
The reason for using more than one node being bad is network latency. You receive each query as an HTTP request and the client does not use keep-alive and opens a new connection for each request. The latency caused by this input mechanism is at least 20 times bigger than the time required to find the answer to the request. Therefore, a) tuning your algorithm yields you almost no speedup due to the high fixed network delay once you use a suffix array or similar structure and b) forwarding the request to other servers allows you to reduce the size of the index but given that the algorithm is logarithmically complex in the size of the index that really doesn’t help much compared to the added latency.
I actually went one step further and also hacked together my own HTTP server to (hopefully) reduce latency some more. Since you receive only one query at a time it does not require threads or forking so it is rather compact. Before, I used an extremely simple HTTP server based on boost::asio.
This was a great task to begin with, I had never used a suffix array before. It could have been even greater though: A score based on throughput and latency as well as say factor 100 more queries and this could have been the only question in the challenge and still be extremely interesting and challenging.
Level 4: Distributed SQLite Cluster
I am a database geek, this is awesome. Although it has nothing to do with databases but is all about distributed systems, but this was to be expected from a distributed systems contest. You are given an implementation of a cluster node with a broken consensus protocol. Your job is to change it such that each SQL query given to any node in the cluster is applied at most once to the cluster state and its state change is never lost. Also, your cluster has to make progress even when nodes fail and links break.
For this challenge, Stripe actually wrote a very decent network simulator called Octopus. It only works using UNIX domain sockets but they give an example of how to use those easily in Go which was used for their example implementation. The reason they probably chose Go is because there is a library implementing Raft, a distributed consensus protocol, for Go. From how their example submission was implemented, go-raft was essentially a drop-in addon which added raft to the cluster. It took me about 2 hours to understand how to plug everything together and raft was working.
Although I now had a join consensus protocol working, the challenge was far from over. Raft is a strong master consensus protocol which means that only the master can issue commands to the cluster. This complicates the solution dramatically, as the simulation used to score this challenge submits SQL queries to all nodes and not just the master. To add insult to injury, the client submitting the requests can not be redirected to submit them to the master due to using UNIX domain sockets (it does listen to 302 found requests, imho, but it does not switch the UNIX domain socket used to contact the master as far as I know). Therefore, each cluster node needs to be able to forward requests to the master so that the master can apply the request to the cluster. This is tricky.
Forwarding requires that a) the query is only executed once and b) the result is send back to the node which initially received the request and then forwarded to the client, also exactly once. I did not see a) coming as I thought network links were only delayed or jitter was applied to them, not disconnected. That hit me hard and I had to rewrite my forwarding protocol. I ended up generating a unique id for each incoming request and handing it of to whoever is currently the master node. The unique id was used so that the receiving node would only execute the query once and never twice. There are edge cases, where the receiver is no longer the master and again needs to forward the SQL query which I dealt with but will not explain here, see the sqlHandler in this file for details.
Result submission was done by tracking which state updates were applied to the cluster. When a query which was originally received at the current node was applied to the current node, the result of that query was also submitted to the client guaranteeing exactly-once semantics for result delivery.
The last part was getting a good (>1000) score. I did this by improving the performance of state chance applications to the state machine modeled by each cluster node. This only occurred to me on the last day of the contest and greatly (5x) improved my final result. Go was very helpful here as go-routines and channels make it very simple to implement this; see this file for more.
I also improved the SQLite database speed by running it in memory, starting it once and sending all queries to the same, permanently running SQLite process through go channels. It’s simple and yielded a huge performance increase in SQL query processing.
Summary
I am happy with my results, apparently I am a pretty decent programmer, 8 out of ~4000 ain’t too bad especially when scores vary by a factor of 3x between executions which makes getting a great score a game of chance. I learned quite a lot during the contest, I can highly recommend solving each problem yourself. Thanks Stripe!
Perf is an excellent tool for profiling linux software. It uses hardware performance counters to give you information on your code’s performance. This makes it a very low overhead alternative to – for instance – valgrind which uses instrumentation. Both ways of profiling software have their merits but perf is a great tool to just keep running all the time to find severe performance bottlenecks with ease.
That said, I frequently have to profile only a part of my code. This is due to the fact that I write lots of database benchmarks which frequently load or even generate an initial dataset which they than run queries on. I usually care for query instead of loading performance, therefore I’d like to profile only the query part of my application. This can be done using API calls to the excellent performance counters C api but in my case, an easier way of achieving what I need it to use a “perf wrapper”. In you code, that wrapper looks like this:
// ...#include "System.hpp"
intmain(){// ...// Load dataSystem::profile("loading",[&](){db.insert(1);db.insert(2);...db.insert(999999);});// Run queriesSystem::profile("queries",[&](){for(inti=0;i<1000000;++i){db.query(i);}});}
For each System::profile part you will receive a performance counter dump, one named loading.data and one named queries.data. Each contains the samples for the appropriate subset of the code and you can find bottlenecks wihin query execution without also seeing all data which is actually produced by initially loading the database.
Essentially, this code starts perf record on the current process right before it’s body is executed and stops perf
right after the body giving you a performance counter sampling of exactly the part of code you are interested in. It is implemented like this:
You can take a look at your results by executing either perf report -i loading.data or perf report -i queries.data depending on which part you are interested in.
Of course, this only works and looks this good if you use C++11 but who would want to use anything less.
Coding challenges are great for anyone who codes, likes to win and has too much time on his hands. I participated in an extensive one earlier this year, I learned a lot. Coding challenges have been institutionalized, one platform offering such challenges is CodeChef. There is different types of challenges on CodeChef. One such type is code golf where the goal is keeping the source code as short as possible, to me, something utterly useless. Short, readable code is great, code like :(){ :|:&};: is not. More interesting challenges are timed, hard problems. I am not the lunch-time challenge type where time limits range between one and a couple of hours but a contest lasting for say a week gets my attention.
From the little if read on CodeChef so far, this seems to be very India-centric in its nature. Universities hold competitions for their students, sometimes there is apparently an Indian vs. non-Indian leaderboard.
The Challenge and a Solution.
If you are starting to code, most challenges will upset you greatly. I chose to try one of the training challenges, rated easy. Algorithmically, that might be the case, from a technical point of view this is certainly wrong. I am fairly certain that the challenge is impossible to solve in any language which is not compiled down to machine code. I am even more certain, that winning (in terms of lowest runtime) is out of the question. This is not because I inherently despise VM-based languages except for trivialities like web programming (I do), but because of the way many contests are run.
Let’s look at the problem at hand first, it is from graph theory, the mathematically disinclined are recommended to skip this paragraph. Given an undirected graph G(V,E) where V denotes the set of vertexes and E denotes the set of edges; edges have an associated weight. For all (v1,v2) such that v1,v2 are elements of V and v1!=v2, find the path p1 which connects v1 with v2 such that there is no other path p2 for which mincost(p2) > mincost(p1). $mincost(p)$ is defined as min( { weight(e) | e \in p } ), that is, the minimum weight which is associated with an edge on the path. Essentially, for every pair of vertexes, one has to find the minimum weight of the path which has the lowest minimum weight of all paths between those two vertexes.
It is immediately obvious that a brute force solution will not yield sufficient performance as the time-limit set on CodeChef is 3 seconds and the number of nodes can be up to one thousand. This means that potentially, (1000*1000)/2 vertex-pairs have to be examined. Luckily, the algorithmic part of this exercise is indeed fairly straight forward. Since we are trying to avoid “cheap” edges with a low associated weight and the number of edges we use on a path is not relevant, we simple need to build a simpler graph which connects all nodes and uses high-weight edges. This is essentially the inverse of a minimal spanning tree (or: a minimal spanning tree with all weights inverted). Given that tree, we just have to generate the all-pairs best paths and have solved the challenge.
While implementing a minimal spanning tree algorithm is fairy straight forward given the abundant supply of examples, even the best implementation of the actual algorithm will not help us onto the leaderboard, let alone be the fastest entry. This is because both input and output are massive in size compared to the work the correct algorithm has to perform.
The input format is
<number of vertexes>
<number of edges>
<from> <to> <weight>
<from> <to> <weight>
...
<from> <to> <weight>
and a simple parser can be written using C++ streams, for instance:
This is very readable code and it does not use evil methods like fscan. Unfortunately, it is also incredibly slow. I submitted a parser like this (without any other code to solve anything) to see how fast it was and it timed out. I was so shocked that I uploaded an empty solution to see if that would time out too – it didn’t.
As with every issue, a quick search on StackOverflow reveals that std::cin is indeed relatively slow. Relatively, as it turns out can translate to 100x, which is the speedup I gained from modifying the parser, my modifications:
Buffer stdin.
Parse numbers without scanf.
Iterate exclusively using pointers.
The resulting reader class with some details stripped looks like this:
classBufferedReader{/// Size of the input bufferstaticconstuint64_tBufferSize=1024*200;/// The buffercharbuffer[BufferSize];/// The current and end pointerconstchar*currentPtr;constchar*endPtr;public:...boolreplenish(){.../* loads more bytes into the buffer */}/// Reads a number from the buffertemplate<classT>TreadNumber(){Tnumber=0;while(true){for(;currentPtr!=endPtr;++currentPtr){if(*currentPtr>='0'&&*currentPtr<='9'){number=(number*10)+(*currentPtr-'0');}else{gotodone;}}if(!replenish())break;}done:returnnumber;}...};
Before you mock the use of goto, breaking out multiple nested loops is actually the only allows usage that does not cause this to happen. Using this optimized parser lead to the submission not timing out but instead failing with “wrong result” – as no result was returned by my implementation so far. The runtime for parsing was returned though and now amounted to roughly 1% of what the competitors had as their total runtime.
The algorithm for solving the challenge can be found in the linked git repository on GitHub. A detailed discussion might follow in a later post but is omitted here to focus on the tooling needed for challenge participation.
For the output of the solution which is a |V| times |V| matrix, I opted for preallocating all memory required for the output and flushing it out in one write. This tremendously simplifies the writer class and should be sufficiently fast for an output in the order of a few megabytes.
The first run of the complete solution worked and yielded a correct result – albeit at a too leisurely pace for my taste: 16.09 (unit missing from CodeChef, that actually really sucks). To be number one on the leaderboard, roughly 2x are required. Quick testing and profiling on a generated random graph shows that some time is spend generating the output. A separate run of the PoorMansProfiler actually reveals, that 50% of the wallclock time is spend writing the output, specifically, calling itoa.
classFixedWriter{/// The output bufferstd::vector<char>buffer;/// The index inside the bufferuint64_tindex;public:/// ConstructorFixedWriter(uint64_tmaxOutputSize):index(0){buffer.resize(maxOutputSize);}/// Writes an int into the streamtemplate<classT>voidwriteNumber(constT&value){//index+=sprintf(&buffer[index],"%d",value);FormatUnsigned<T>i(value);// <= see github repo for implementation!for(constchar*ptr=i.c_str();*ptr!='\0';++ptr){buffer[index++]=*ptr;}}/// Writes a charactervoidwriteChar(charc){buffer[index++]=c;}/// Flush to fdvoidflush(intfd){autolen=write(fd,buffer.data(),index);assert(len==index);}};
Googling “optimizing itoa” actually yields plenty results and is left as an exercise to the reader. The finished output writer is displayed here for reference. The key part is swapping out sprintf for an optimized routine inspired by the more complete one authored by Victor Zwerovich (GitHub).
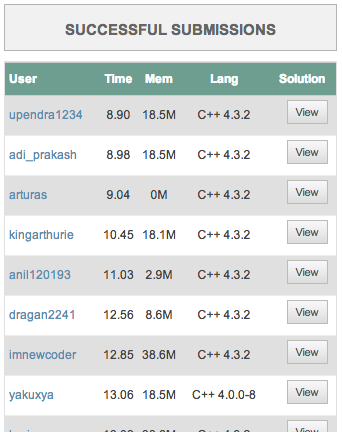
And alas, 2x, top of the leaderboard. Remember, the problem was classified as easy. I figure much of this code is not entry level code. A better metric for determining the difficulty of a task is probably the number of successful submissions.
For this one, it is less than 50 entries, some tasks have thousands…