I’ve recently switched all my families accounting from manually looking at
bank websites + mint.com to Ledger.
This post describes the first part of that fairly long but ultimately successful
journey: Motivation and Challenges.
Motivation A: If your bank dropped $1,000 from your account, would you notice?
I think my dad would have. He had all statements printed. In Germany, you do this
at a small machine in the bank building (or you have the printouts mailed to you)
and by putting them into a folder, you see old and new balances as well as the
transactions between the two. This presumably makes spotting that something is off
fairly easy.
For me, this is probably a no. My checking account balance is usually fairly
high since our rent is payed by check and
is a few thousand dollars
that have to be on the account when the check is cashed. Some days, I would
probably notice a thousand dollars missing. Other days I wouldn’t.
Worse yet, I just read an intriguing email thread at work where someone’s bank
took credit card payments for someone else’s credit card off of their checking
account. The colleague who, quite embarrassedly actually, reported this, did not
notice the $100-ish payments which did not belong to them going out of their
account for 5 years. I think this is not completely unlikely to happen for
others as well.
Now does this mean that I am losing money from my bank misreporting my balance
or payments going out that shouldn’t? Probably no, but at the same time I feel
I might just not notice which is bad.
Motivation B: How many accounts do you have and what is the sum of all balances?
This sounds like a fantastic problem to have but realistically I simply don’t
know. We have 5ish credit cards in the US, we have 3 credit cards in Germany,
we have 2 checking accounts in the US, 2 checking accounts in Germany, we have
401ks, we have all kinds of other weird financial products and very little cash.
And really the only reason that I know we have all these random accounts is
because I just put all of this into ledger. This is part of why this is
important and cool work. You actually have one place that is aware of all
accounts and it knows how to deal with different commodities and convert between
them so you can get a digestible picture.
Mint partially solves this. If you only have accounts in the US and all of them
work with Mint, then this could be a decent tool. I never much cared for many
parts of the interface but if you are comfortable with it and Motivation A
doesn’t matter to you then this is probably not the worst solution.
Getting from Mint to Ledger.
I made one simplifying assumption first: I won’t care about the past. While this
is not at all true, it just didn’t seem worth it to import a year or more of
past transactions and categorize them from scratch. Granted, it would give
insight into past behavior but the last two or so months are probably sufficient for
that.
Then I needed to solve the most fundamental issue: How do I stop myself from
starting entering things in Ledger and then stopping 2 weeks later when it
becomes a chore. My solution to this is automation. I do not enjoy copy and
pasting stuff from my bank’s website. Neither do I want to log into 5 websites
every three days just so that my finances are up to date. What simplifies this
is that we really only use one credit card frequently, one checking account
and one bank in Germany. It seemed reasonable to automate all transaction
downloading for three financial institutions and maintaining that code. With a
little luck one might even be able to find a second person who would help
maintain that if open sourced.
What I’ve ended up with now is a solution consisting of:
Ledger file in Dropbox.
Automated downloading of transactions from
Chase,
our Credit Union, and
our German bank.
Automated report generation from the ledger file.
The next post will talk about the implementation of the automated downloader
for Chase as this had about the most caveats. The code will go on Github when
that post is ready.
Expressions occur naturally in many languages, for instance in SQL. Usual ways of executing expressions are by interpretation or code generation. While I want to eventually talk about code generation, a sensible first step approaching expressions is parsing them from text which I will discuss in the blog post.
Looking at a SQL statement, we find multiple expression but will first focus on the one used to find qualifying tuples which comes after the WHERE keyword:
While the expression given in this example might seem slightly manufactured, the takeaway is that such expressions can be
nested,
common operator precedence rules like addition binding less strongly then multiplication need to be observed, and
types might need to be inferred.
Starting from the string representation of the expression, it must first be converted into a format which is suitable for further processing by a parser. While parsers can be hand-written, and some people argue that this is a good idea (e.g., here and here) it is definitely not a fast way to get started and hand-written parsers do not work well when the language definition is not quite clear in the beginning. This calls for a parser generator which takes a BNF-like description of the language to be read and converts it into a program which can then parse that language and trigger call backs or - ideally - generate an abstract syntax tree (AST) representing a input.
While tools exist which create a parser which has an AST as its output, I am not aware of any free, stable and up-to-date tool that generates a C++(11) AST. In java, I used ANTLR many years ago and it is capable of creating an AST and also specifying rewrite passes for that tree but unfortunately ANTLR is very heavyweight and does not sport a C++ (let alone C++11) generation target.
Wikipedia offers an extensive list of parser generators, however many are not maintained anymore. For my purposes, it seems like BISON would be a good contestant but I usually assume a smaller project size and language complexity so I frequently use less fancy parser generators based on parse expression grammer (PEG). For this blogpost, we will be using packcc (original version) because it is the only PEG based parser generator I am aware of which is capable of parsing left recursive grammars by implementing the approach mentioned in this paper from ACM SIGPLAN 2008.
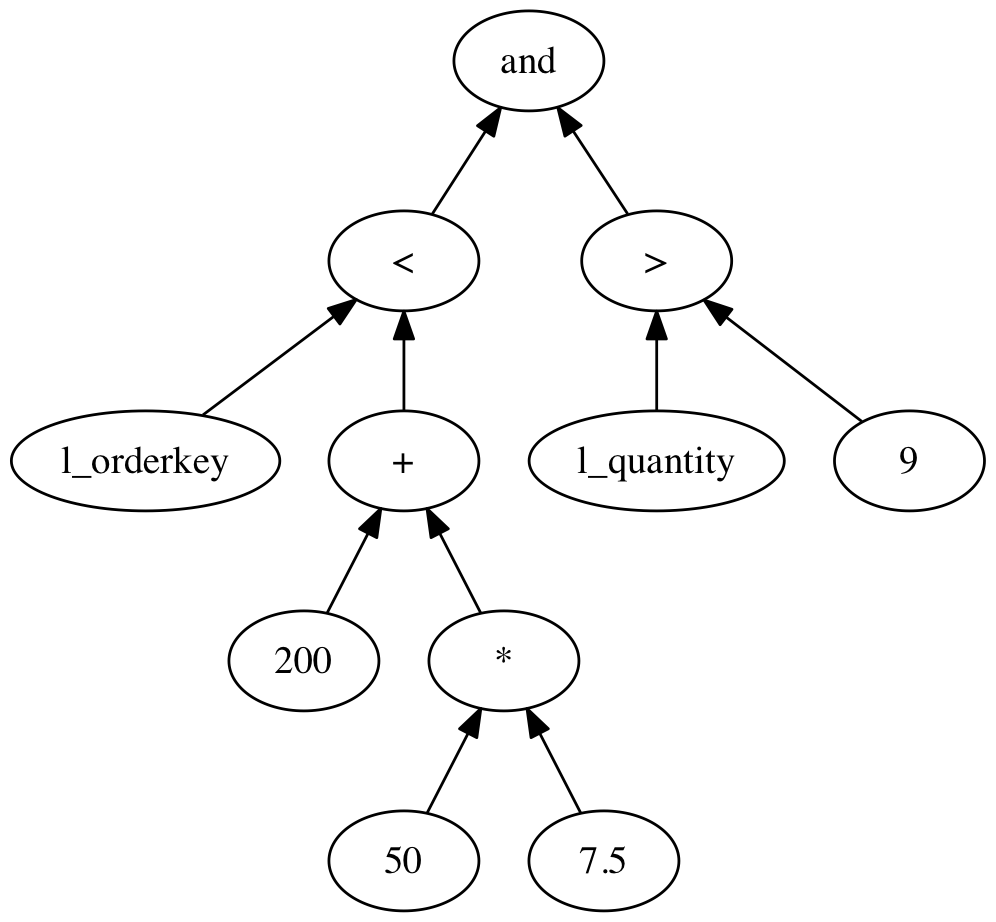
Looking at the expression from the beginning of this post without the SQL boilerblate:
l_orderkey<200+50*7.5andl_quantity>9
we will focus on simple arithmetics, comparisons and two types, int32_t and double. Writing a grammar acceptable by packcc starts out be defining helpful rules for skipping whitespace and detecting literal values:
Since the parser generated by packcc is directly applied to the input string, there’s no tokenization step which takes care of converting all characters into neater tokens. Instead, we essentially define regular expressions for the building blocks of our language, in this case ints, doubles and whitespace. Naming the whitespace rule _ is convenient since it will be used around most rules in the program at each position where whitespace can be tolerated in the input. The additional whitespace rule named __ here is an extremely awkward detail of using a parse expression grammar parser generator. It means we will tolerate whitespace, however we do not tolerate 0 or more characters of white space but instead ask that there is at least one non character symbol. This is important to force parsing operators like or and and correctly without enforcing whitespace in many more places where it is not helpful.
Continuing with our grammar, let’s next express addition and multiplication:
op_cmp <- '<' / '>' / '='
op_add <- '+' / '-'
op_mul <- '*' / '/'
cmp <- cmp _ op_cmp _ add
/ add
add <- add _ op_add _ mul
/ mul
mul <- mul _ op_mul _ prim
/ prim
prim <- literal_double / literal_int
These rules encapsulate both parsing of comparisons, additions and multiplcations as well as operator precedence. If possible, a comparison will be parsed first. If that does not work, we try to parse an addition which binds more strongly than a comparison. If that doesn’t work, we try to parse a multiplication, which binds even more strongly. If we can not parse a binary expression, then we will try parsing a prim which is currently either a literal integer or double. Note that the order in which prim is specified is important in PEG. Otherwise, we would parse the numbers before the decimal point as an integer and then fail to continue. The double has to be parsed first. In hindsight, not using PEGs and resorting to a GLR parser generator like BISON might help avoiding this kind of issue for more complex projects.
Bringing it all together, we add a top-level rule which parses an expression potentially surrounded by whitespace
expr <- _ add _
and some boilerplate and we have a first cut of our expression parser. Adding variables and more operations to this is straight-forward. Unfortunately though, the parser does not do anything intelligent with the input except determining whether it is in the language or not.
To convert the input string to something more usable, most yacc/bison style parser generators allow the grammar to be annotated with actions to be performed when parsing a particular rule succeeds. Many first expression examples use these annotations to implement a calculator. While this might look nice, it is not a scalable way of implementing anything on top of a parser. The way to go is to convert the input into a tree like representation, usually referred to as an abstract syntax tree. The idea is to convert each node into a tree node containing other tree nodes as its children, a representation closer to this:
This tree structured representation of the parser expression can be implemented as a pointer structure between node classes, something similar to this:
As a side-effect of parsing, using annotations to the grammer, this representation can be constructed and then much more easily handled in the remainder of the program. It usually pays of to write a generator for AST nodes since then infrastructure methods like dumping the tree to dot or adding the visitor pattern to the tree are less time consuming and new nodes can be added with ease. I hacked an AST node generator a couple of years ago but one can be easily hacked given a few hours of time.
Now that a simple expression is represented in a machine friendly format, we can focus on transforming, interpreting and code generating in upcoming posts. The dot example and the grammer with a tiny runner can be found here.
A while ago, I stumbled upon a
guide to writing optimized C code.
I had read a few of the ideas before and previously discounted them as “something the
optimizer should really do for you”. In this and the next few posts I will take
individual pieces of advice and fact check whether rewriting your code as
suggested actually helps or not.
Let’s start with a simple proposition: Counting down to zero is cheaper
than counting up. A similar proposition is sometimes encountered which this
post will investigate as well: Comparing != (not equal) is faster than
< lower than in a loop.
This should be easy enough to code, benchmark and look at the assembly. Please
scroll down to the end of the post for a full disclaimer and test environment
discussion.
As you can see, the code executes the same number of noops but the up
implementation is counting up and comparing using lower then while the down
implementation counts down and compares not equal with zero.
What do you know! Same exact thing. Does this mean subtraction and lower then
versus not equal is equally fast on this machine? Let’s look at the assembly:
Yep, it looks like I objdump -Sed the same file twice, however, I did not.
This actually generates the same assembly. Even cooler, it generates completely
different assembly with -O0 but optimizes to the exact same assembly. Our
benchmarking results make a lot of sense.
Therefore, both
counting down to zero is cheaper than counting up, and
comparing != (not equal) is faster than < lower than in a loop
are
busted for cases where the compiler is free to make this optimization.
One must not discount that compilers have advanced quite a bit
in the 10 years from the time the article I referenced earlier
was written but this is still great to know. I remember at least one occasion when someone
suggested rewriting a somewhat hot loop this way and this basically tells us
that – as long as the loop is changed the way it was changed here – it’s
probably not gonna lead to anything whatsoever. While the whole idea of rewriting
a loop construct like this is only sensible for the absolute hottest of loops,
counting down is not a bulletproof solution.
Before we look at the case when the compiler can not optimize the loop, let’s
quickly check the results on more common platforms.
Other platforms:
Intel® Xeon® CPU X7560 @ 2.27GHz, gcc 4.9:
0.089669005 seconds time elapsed ( +- 0.01% )
0.089674167 seconds time elapsed ( +- 0.01% )
Interestingly, this machine counts down but also optimizes both programs to the
exact same assembly. A guess as to why this is done is because mov can actually
take the constant 0x5f5e100 as an immediate, therefore the compiler saves one
register.
Loops with a data dependent body – from C to machine code
Wisely, Thomas Neumann suggested
going beyond whether writing your C code nop loop in a “count up” or “count down” manner
matters. This adds a much more important question that has so far not been
neglected in this writeup: What if the compiler simply can not change
the way your loop is counting because you are actually using the loop variable inside
the loops body in a way that does not give the compiler the freedom to change
the direction of the loop.
To generate a sensible benchmark for this deeper investigation, we examine
the instructions required to count up versus
down and stop gcc from optimizing one into the other. From the previous
examples, we assume that there is in fact a difference in terms of execution time
of the instructions used to count up versus those used for counting down. If there
was none, gcc would likely not go through the hassle of optimizing one into the
other (and in different directions as well: ARM gcc converts to loops counting up,
the two x86 platforms examined convert to instructions counting down).
In C, we go with Thomas’s suggestion (see code on GitHub, shortened here for
readbility) and implement the benchmarks along the lines of this C code snippet:
This looks really great, however it is on x86. For ARM, the C code leads to
terrible code being generated. For the purposes of this evaluation, we will
therefore not look at ARM for now as the arm benchmark would require manually
written (inline) assembly.
Measuring this on the same Atom CPU used above, we get the following results:
count up: 0.114563958 seconds time elapsed ( +- 0.92% )
count dn: 0.112721510 seconds time elapsed ( +- 0.24% )
insn up: 0.166884574 seconds time elapsed ( +- 0.28% )
insn dn: 0.113022031 seconds time elapsed ( +- 0.51% )
insn lt: 0.193557023 seconds time elapsed ( +- 0.31% )
Quite obviously, counting down is the better choice on this machine (Intel Atom)
when it comes to machine code. This is also visible in the fact that insn_down
requires one instruction less as seen above. Also, gcc makes the right decision
and optimizes both ways of expressing the loop in C to the faster option
Running the same benchmark on the Intel Xeon mentioned before, we see a completely
different picture, first the assembly:
While the assembly is again one instruction shorter for the countdown loop, the
benchmark results paint a different picture:
count up: 0.089699257 seconds time elapsed ( +- 0.01% )
count dn: 0.089653781 seconds time elapsed ( +- 0.01% )
insn up: 0.089669413 seconds time elapsed ( +- 0.02% )
insn dn: 0.089669189 seconds time elapsed ( +- 0.02% )
insn lt: 0.089663413 seconds time elapsed ( +- 0.02% )
All implementations are equally fast. Regardless whether the loop is expressed in
C as counting up or down and also regardless whether the machine code used counts
up from zero or down to zero, the performance of the loop is exactly the same.
Summary:
In summary, we can say the following: If the compiler is free to choose the
direction in which the loop counts, you don’t need to worry – it will do the
right thing. If a data dependency stops your loop from being optimizable in this
fashion, the question becomes more interesting. On a fairly wimpy core like my
Intel Atom, couting down and comparing for (in-)equality was faster. On a premium
CPU like the Intel Xeon tested here, it did not matter at all, all implementations
of the for loop were equally fast.
As a general take away, one should also remember that the difference (if there is one
on your architecture) between
the direction of the loop only matters significantly if there’s next to no work
being done in the loop’s body. For instance, if you were to access memory in the loop, this will likely completely
dominate the cost of executing the loop.
Disclaimer and test environment:
Unless otherwise noted, all measurements quoted here were taken with this setup:
I am trying to write down everything that I remembered to do before leaving for the US so that posterity can benefit from it. I will add what I forgot later on.
DMV Report, Car insurance report
I have requested a report from my file with the Germany equivalent of the DMV just in case. I also asked my car insurance provider to send a letter stating that I am in good standing with them and have not had them pay for anything in the last 11 years. Apparently, some auto insurance carriers in the US will give you a discount if you can provide such information but no matter if useful or not things like this are easier to do before leaving.
I wanted to register for Zipcar back when I was in Atlanta and needed the letter from the DMV which was excruciatingly hard to get since I had to mail things back and forth using USPS and my parents had to forward the letter back to the US.
Cancellations
We had to cancel our newspaper, the internet provider and lots of insurance. Many of these are tricky as there might be a mandatory term on the contract. In Germany, though, most contracts can be canceled at any point in time if you move, especially if the service you were subscribed to is not available at your new address. Debating availability of service when moving from Germany to the US is usually quick. The required documents, though, suck. You have to provide a confirmation from the government that you gave up your residence address (notice of departure confirmation). This document is only issued to you when or after you move so for us, my parents will probably have to mail it to everyone concerned by us leaving. Some people can be persuaded to accept a letter confirming cancellation of your lease but not everyone.
Weekly newspaper: Cancellation at any time.
M-Net Internet: Three months notice, must provide cancellation of lease AND official notice of departure letter.
HUK Medical Insurance: Official notice of departure letter.
HUK Personal liability insurance: Three months notice, revoked cancellation as the insurance works in the US as well.
Luckily, car insurance automatically ends with selling a car in Germany so that’s taken care of.
Taxes
I prepared my tax filing for last year as early as possible this year. First, I have all the documentation handy and second I received all returned documents at my home address. For next year, I have already scanned everything that might be important from 2014 and will leave the original documents with a friend. For the year you move you will have to prepare tax filings for every country you have earned money in. Germany has a double taxation agreement with the US so it will likely not be too bad.
Insurance companies
I opted for getting a prospective entitlement with many insurance carriers. You will be a small fee for keeping your contract running without any actual insurance coverage. This will allow you to reinstate your original contract with no questions asked should you return. In Germany, health insurance is very good and prospective entitlement is cheap. I literally asked my carrier if the entitlement contract means that “as long as I make it back across the border I can be unbelievably sick and will still be covered as soon as I return” and they agreed. Also, in Germany, you will not be able to get back into the mandatory insurance program if you earn more than a certain amount of money once you return. Although there are loopholes everywhere I prefer knowing that I could return at any time without a problem.